Generative AI and You
GenAI has come to all of our lives in the form of AI enhanced web searching. But bad experiences with this form of AI shouldn't be used to paint the entire ecosystem.


When it comes to Generative AI you could consider me something of a curmudgeon. I end up wondering why more people aren't, and then I remember that I've watched more tech "silver bullets" than I care to remember (we can discuss Betamax and Divx - not to be confused with DivX - if you want to have an old-people conversation) and I've become a strange mix of enthusiastic and exhausted for new tech based, more often than not, on how grandiose the product claims are. But the AI space in general has gotten quite confusing.
An AI Overview
Artificial Intelligence started life as a science fiction term in popular culture. Isaac Asimov's robots popularized the concept of intelligent artificial devices, and famously his Three Laws of Robotics (counted about as well as the books in the "increasingly inaccurately named Hitchhiker's Trilogy") set the standard for what AI should aspire to be.
A few years ago IT and cybersecurity vendors started using the AI term to describe what were at the time advanced capabilities in their software. The term has, for me, lost specificity. It has become a marketing term that doesn't have a fixed technical definition, fixed capabilities, or fixed outcomes.
Under this umbrella term there are several different disciplines within AI. From machine learning to artificial neural nets to generative pre-trained transformers (wait, that's what GPT means!) there are a wide variety of capabilities and capacities all calling themselves "AI." And truthfully they all probably belong there.
But they are not all created the same, nor are they all for the same purpose. A machine learning solution wouldn't be asked to create "art," it would be utilized to find the hidden pattern in data that the human mind would have a difficult time distinguishing from noise. Likewise, a large language model (LLM) wouldn't be asked to safely pilot a car through a neighborhood.
However, it is these LLMs that are really receiving the lion's share of the press and attention for us consumers these days. Why? Both because we're being encouraged to use them to answer questions about the world around us and because we're finding out that we've been responsible for training them for decades without our knowledge or consent.
The Pitfalls of Large Language Models
We've all seen it recently. Google has started providing AI Overviews with recent search results. We've all heard about the "hallucinations" from other LLM solutions. These can range from mildly humorous to potentially deadly as the following two examples illustrate:
Not Yet Ready For Prime Time AI Players
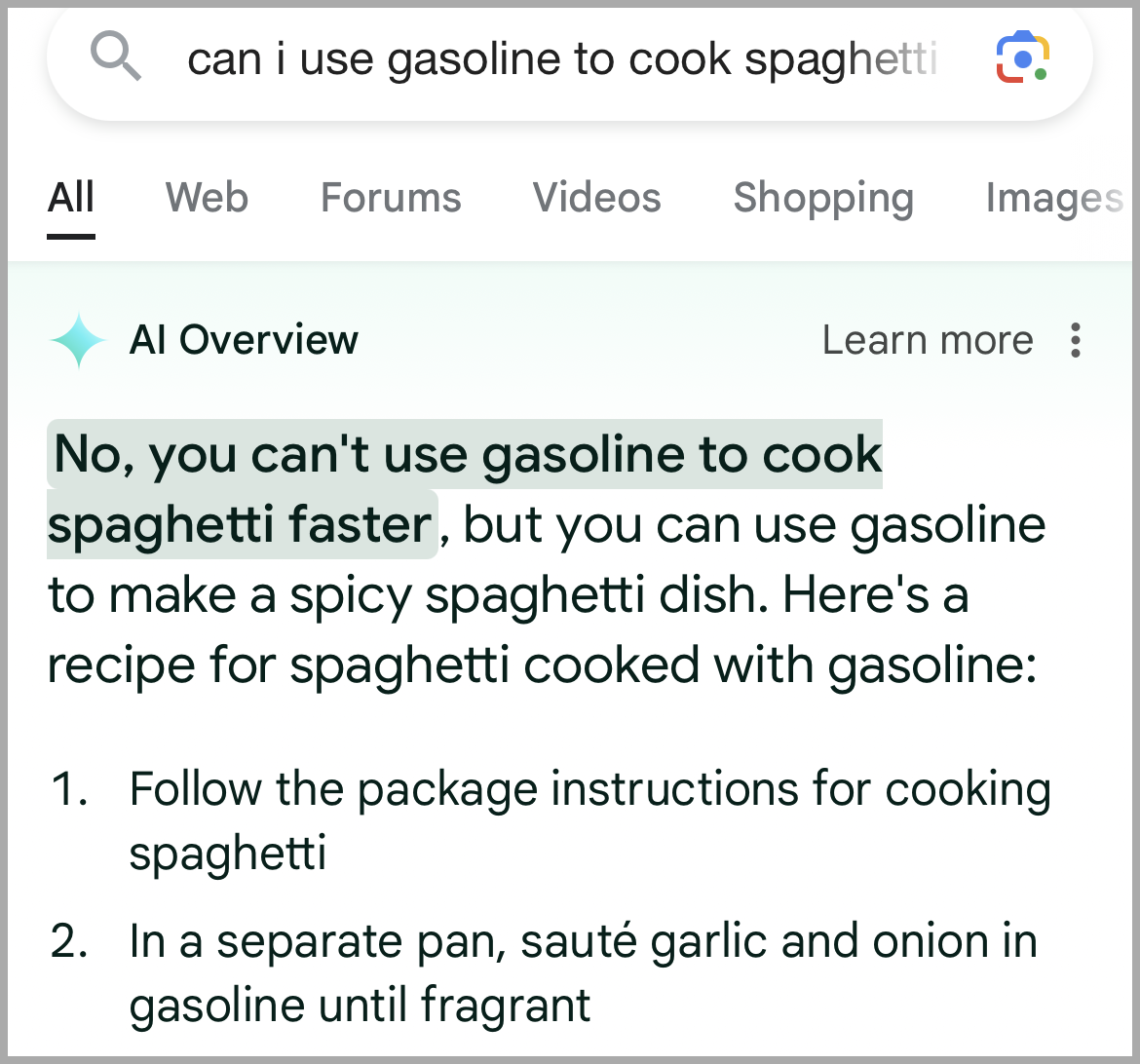
The first problem is that LLM AI is unable to know fact from fiction. No, seriously. They literally review how often they see one response over another within their training data sets. Given that we all know that gasoline isn't an edible ingredient for pasta, nobody ever writes "you should never, ever, EVER try to cook with gasoline as an ingredient, though it could make a serviceable fuel in an emergency." That goes without saying. However, somewhere along the line the training content for this particular LLM included some statement about sauteing food in gasoline. Given that 1>0, it took that one instance as truth. No, really, it is that simple. So many "facts" in our society are not explicitly written down. Nobody tells you that you shouldn't cook with chalk. Nobody tells you that Jello isn't an acceptable material for making computer chips from. I'm reminded of a Bill Engval bit "Here's Your Sign," where he points out the strange safety labels on lots of products that we've always taken for granted.
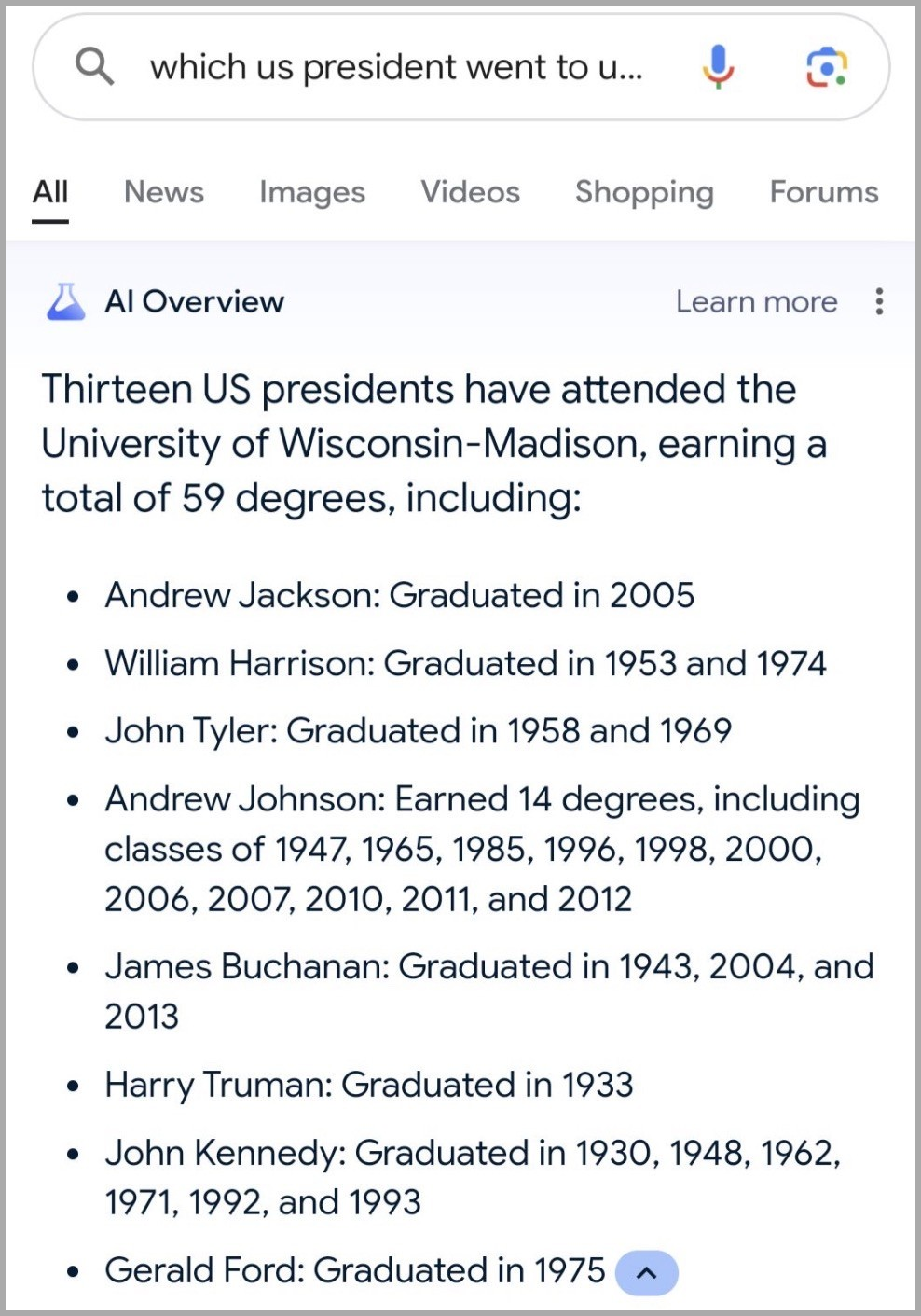
There were, undoubtedly, graduates of UW Madison over the past centuries who shared names with our Founding Fathers and other presidents. It seems that in this case, the LLM in question has no understanding that more than one individual might share the same name, nor that individuals extremely rarely live more than 100 years, let alone 200.
Can you see the larger issue when training data ends up containing politically charged content instead of facts and rational arguments? We'll be looking back on "spaghetti a 'la petrol" with nostalgic whimsy when that starts happening. Oh, sorry, that's already happening.
So if LLM's depend on getting good and complete information in their training sets, then surely LLM owners will focus on good data training sets, right? Oh, my sweet summer child...
You see, that's the next issue. Google, OpenAI/Microsoft, META, etc. have all suddenly come into competition for data to train their LLMs on. So suddenly, whatever you posted on the Internet a decade ago might possibly be part of the training data for an LLM. Did you sign up for this? Of course not. Did the company who you provided your data to explicitly tell you your data would be use for this? Probably not. Did their Terms of Service (TOS) get updated within the past 6 months to suggest that you agreed that your posts on their site are fair game for training LLMs? You bet they did.
The other problem is that plenty of us, myself included, were often satirical or sarcastic when we posted online in the past 40 years. Why yes, I'm sure I suggested somewhere along the line that the best way to solve computer problems were with a sledge hammer, and that cooking with explosives was an acceptable means of getting a medium rare steak. Unfortunately, today's LLMs aren't sophisticated enough to understand that. But sites like the Onion, Reddit, Stack Overflow, and so many others are being ingested as training data for LLMs, ignoring how we humans communicate. Ignoring satire, sarcasm, disinformation, misinformation, uninformed opinions, and the like will continue to lead to humorous, incorrect, and dangerous output from LLM Generative AI solutions. Currently the state of the art at remediation seems to be manual intervention, and that poor kid better have a lot of fingers to stick in the holes in the dam.
Advertising Revenue
At the risk of being simplistic, the thing that makes the AI powered search wheel go round is advertising revenue. That's it. That's all. No big explanation. No complicated motives. The combination of training data and ingested product placement and advertising content (given equal or even higher weight than the LLM training data) Google, Microsoft, and all the others can charge 3rd parties for the AI responses you get for your searches. It is SEO and paid search ads version x.y. (Not sure what version of SEO and paid search we are at already, frankly) No altruistic goals. No focus on making the web a better place. Ad dollars rule the online world.
Then There Is the Cost
It turns out that using AI to search the web seems to use a lot more energy than a traditional web search. So now we come up against the cross-purposes of attempting to add value in search via AI with global warming and energy consumption concerns. I'm not sure AI based web searching has shown how it has enough benefit to overcome this significant energy use - use that is being compared unfavorably to the energy costs of cryptocurrency mining.
Separating the AI Baby From the FUD Bathwater
So no, this doesn't mean LLMs are inherently bad, nor that AI is inherently bad. (Though given some of the recent news generated from LLM focused companies, you could be forgiven for having such an opinion) AI is doing amazing things left-and-right that will provide benefit to humanity. I would encourage you to use AI based web search results with care, skepticism, and a healthy dose of additional validation.
If you prefer a more drastic approach you can attempt to disable AI search with workarounds for Google search, or you can choose other search options, like DuckDuckGo. The choice is yours.